- 4 Posts
- 8 Comments
Joined 2 years ago
Cake day: November 1st, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.

 1·2 years ago
1·2 years agoYes, if you build an embeddings database with your documents. There are a ton of examples available: https://github.com/neuml/txtai
It works with GPTQ models as well, just need to install AutoGPTQ.
You would need to replace the LLM pipeline with llama.cpp for it to work with GGUF models.
See this page for more: https://huggingface.co/docs/transformers/main_classes/quantization
Thank you, appreciate it.
I have a company (NeuML) in which I provide paid consulting services through.
Well for RAG, the GitHub repo and it’s documentation would need to be added to the Embeddings index. Then probably would want a code focused Mistral finetune.
I’ve been meaning to write an example notebook that does this for the txtai GitHub report and documentation. I’ll share that back when it’s available.
This code uses txtai, the txtai-wikipedia embeddings database and Mistral-7B-OpenOrca-AWQ to build a RAG pipeline in a couple lines of code.
Thank you, glad to hear it.

This is an application that connects a vector database and LLM to perform RAG. The logic is written in Python and available as a local API service.
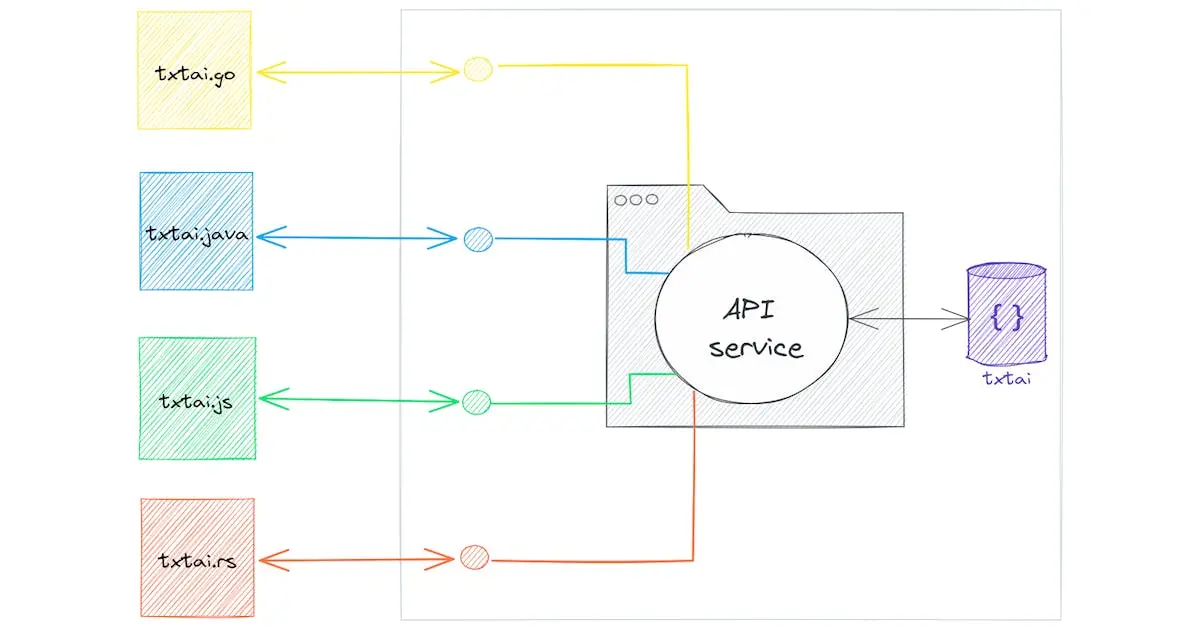
I haven’t found one that is universally best regardless of the benchmarks. Same story with vector embeddings, you’ll need to test a few out for your own use case.
The best one I’ve found for my projects though is https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca and the AWQ implementation https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-AWQ.